Failure is Not an Option (a.k.a. The Graceful Recovery of Scheduled Batch Processes)
“It just failed,” is hardly an appropriate response when asked why a critical batch process failed. As quickly as possible, you need to know why it failed, and put a recovery process in place. Your team spent valuable time defining your batch processes, so it makes little sense to burn time each time you encounter a failure.
The best way to handle job failures is to plan, from the start, for a number of likely causes. The core structure of a JAMS Job includes a section for recovery processing to ensure that businesses have specific procedures to protect a schedule from common IT operations issues such as missing files on an FTP server, missing data within a database, or any number of other reasons.
Automated recovery is often overlooked when defining a job and many scheduling tools lack the feature set needed to handle failures gracefully.
The Recovery Properties of a JAMS Job provide a variety of intelligent methods to mitigate the fire drills that plague IT departments.
If Minimum Completion Severity
Not all errors are alike. One feature of an enterprise scheduler is the ability to separate the nuances of particular errors. A job may complete with errors, but that might not mean that you want to bring your whole process to a halt, especially if another job is waiting on its completion. Completion Severity separates the most serious problems from the nuisances.
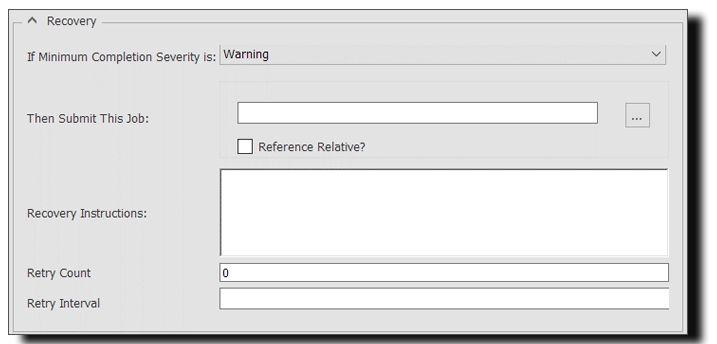
Then Submit This Job for Automation Recovery
Job failure is one of the most basic triggers to keep a centralized schedule optimized. If you have a reusable solution to a common failure, it can be stored as a Recovery Job and run automatically as a response to that failure. A single recovery job that resolves even 10% of a job’s failures can save an organization hours of troubleshooting. Recovery Jobs can be used to restore data within a database, restart servers automatically, move files to a separate error location and more.
Retry Counts & Intervals
Smart IT managers don’t give up after one try. Neither do enterprise schedulers. In JAMS, failed jobs can be retried multiple times at a frequency you define. Retries may not reveal the root cause of a failure, but they can compensate for lapses in connectivity, late file deliveries and other minor offences that don’t merit your valuable time to investigate.